

Incredible thoughts of the week #54
I'm Mr. Meeseeks, look at me!

I said I’d come back for notable things. To be honest, there have likely been some notable things I could have written about, but with all the excitement around DeepSeek’s LLM I figured it was worth writing about.
🤖 💥 DeepSeek’s R1 upends gen AI landscape
🐶 📍 Claude adds citations (this feels fairly lacklustre in light of the DeepSeek announcements, but I’m mentioning it as it is relevant to the conversation)
DeepSeek
Almost all the news this week has been about the DeepSeek’s announcement of their new LLM model R1 that apparently matches, and in some areas beats, the leading state of the art LLMs at a fraction of the cost.
To summarise the current lie of the land:
DeepSeek is a Chinese tech company who have announced this model - with restricted access to American chips, they have apparently trained their model or lower spec and at a far lower cost (claims of training costing $6m, which is way lower that SOTA model costs). These claims are (as far as I know) yet to be verified, but as they say necessity is the mother of innovation.
It’s a reasoning model - so closer to the approach used by OpenAI’s o1 and o3 models. Taking it’s time to “think” - asking it questions, it outputs its chain-of-thought processing (it thinks out loud).
It’s more Open Source then any other models - they are sharing their model weights (the maths) and have licensed the tech with a very permissive MIT license. Between the permissive licensing and the low API costs, it hugely reduces the barrier to entry (financially). They have also published a paper with their methodologies creating the model
Why is this interesting?
Anytime an LLM comes out that leapfrogs almost the entire market in terms of benchmarks, people sit up and listen. When the model that has done that is also claiming to be a fraction of cost to use and (apparently) to train, people listen even more.
It has also upended the assumptions that American tech and AI are leading the way with OpenAI previously the heir apparent.
What are people saying?
Anecdotally it does indeed seem to perform well at reasoning tasks, but I’m yet to see anyone giving it a vigorous testing. I’m sure the community will benchmark it further and dig into it. The transparency of the chain-of-thought is apparently attractive, but to me that feels like polish (I get that it can be re-assuring to see a “thought process”, but given its still just output from an LLM, I’m not sure that it adds value to the outcome).
The connections with China, does of course raise some questions - and in any highly regulated industry, there may well need to be some serious due diligence done before anyone trusts it with their data. I suspect very few will be happy going straight to their API (to be honest, I’m not sure many companies would be happy with their data going to OpenAI APIs for that matter - I suspect privately hosted cloud will be the only option), but more widely it may take some time to see adoption.
Artificial Lawyer has been collecting views on the announcement from the legal industry, which gives a good rounded insight from people on the ground.
What am I saying?
The China connection is undoubtedly going to be problematic for many companies and industries - even if you are hosting it privately, there are going to be questions and perceptions regarding the use - especially with the limited widespread understanding of how LLMs work, I’d not be surprised if there is a lot of caution around this uncertainty. Likewise, I’d expect a number of companies may have a blanket ban on its usage until it is better understood. If you are unable to convincingly explain to a customer how an LLM tool is working, it won’t be easy to convince them that there definitely isn’t anything dicey buried within that magic box.
However, what is more interesting, in my view, is that they have published the paper and model openly - given the claimed costs to train and run, I’d bet every single company training LLMs have diverted a bunch of effort into verifying these approaches. If it all holds up and verifiable, then you’d assume OpenAI et al will come out with comparable models using similar techniques, in due course. As I have been telling people at every opportunity in 2024, LLMs are becoming commoditised - they are essentially just cloud computing resources. An LLM in the market moves, they will likely all follow suit.
The other obvious point this highlights is another common theme I’ve talked about for 2024, LLMs aren’t super defensible. For the most time, capital has been the moat (it takes a tonne of cash to train models) - but even that seems to have been undone with DeepSeek (again, let me add the caveat: only if all this news is true - it wouldn’t surprise me if there was some smoke and mirrors here. As has been noted elsewhere, the timing with US presidential inauguration etc they could be taking the hit with a typical loss-leader model).
Assuming the techniques are verified and reproducible, this is likely great news for all of us. For those building at the application layer, reduced LLM costs are going to make it a lot easier to build value into your platform (at the price of OpenAI’s O1, you might have to be fairly convinced that the value it is adding is worth it, for example).
Eventually, all these LLMs are likely going to be operating at marginal cost and competing on feature-set and performance for your specific task, just like any cloud resource.
Testing it..
For fun I asked it my regular question about Welsh rugby. You can chat with it in a very ChatGPT style UI at chat.deepseek.com - but let me add my usual caveat: Only sign up if you are comfortable with it, and DON’T ENTER SENSITIVE DATA (I know I shouldn’t have to say that, but I know these things are fun and exciting and we can all get carried away. Consider this a blanket rule: Don’t enter sensitive data to ANY random site on the internet).
It was pretty wordy, Im not sure I like the style of how its going back and forth with itself:
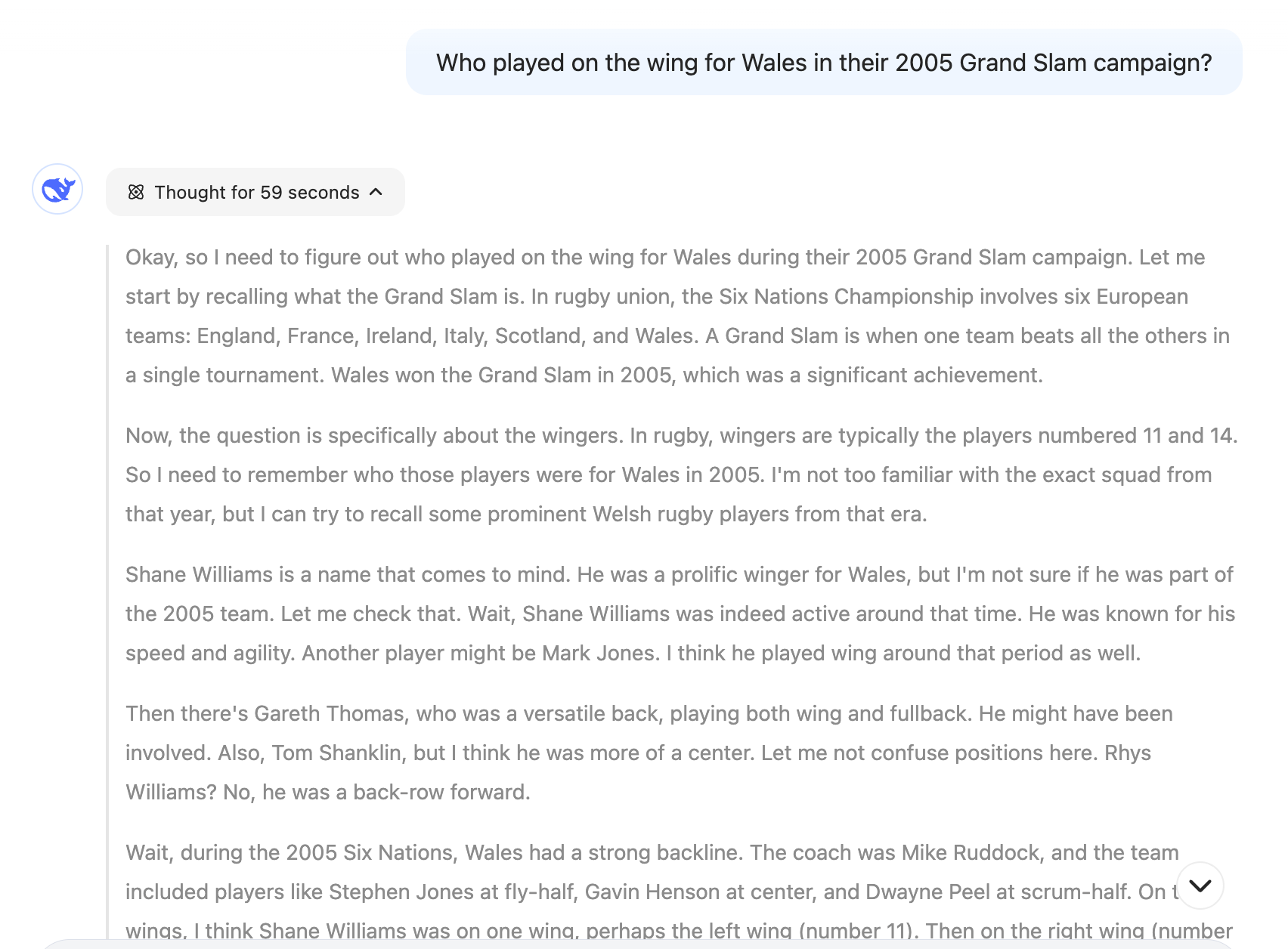
It did get itself confused a few times, and it thought for a long time (several more pages of the above, going back and forth on “oh wait”). It also seemed to repeatedly get Rhys Williams (a winger for Wales, who did feature 2005 Grand Slam) with Martyn Williams, a flanker (back row forward of the same era) for some reason. It also seems to just litter in random facts it knows that aren’t seemingly relevant to the final answer (but maybe thats the nature of a good back and forth, exploring adjacent facts)
The final answer it gave was ok, but not correct (Mark Jones didn’t play at all in 2005 Six Nations, but did play later in that year for the team):

I’m sure to actually test it’s capabilities, a question that involved actual reasoning would be far more suitable (this is a test of memory, so not really sure that it can be reasoned the same way - it should probably just go through players and pick what it thinks is most probable), but this isn’t really testing any performance, this is just for the bants.
Speaking of messing about, I decided to put a similar prompt into ChatGPT - to be clear, this is just prompt engineering tricks to make the LLM “think out loud” in a similar way to how DeepSeek output is formatted.
The prompt:
I'm going to ask a question and I want you to answer in the following format:
1. Before "answering", I want you to think out loud by writing down your thought process
2. For the "thinking" period wrap the output in <thinking></thinking> tags. When you come to answer it, wrap the output in <answer></answer> tags
3. When you answer the question, I want you to really break it down - breakdown the question being asked and your assumptions. As you think, I want you to review it as you go, and review your previous assertions in a chain of thought.
4. Once you have finished "thinking", before answering, write down how long (in seconds) you have spent thinking about the answer.
My question: Who played on the wing for Wales in their 2005 Grand Slam campaign? The response:

The only reason I’m noting this is that it felt like the reasoning was fairly similar in approach (and different to me - I’d never think to myself, “ok, what numbers are the wingers”, as I don’t think the human brain works like that.. mine definitely doesn’t)
Claude adds citation
As noted, this feels fairly low-key in comparison to a potentially state of the art LLM that has dropped at a fraction of current SOTA train and run cost, but I’m adding it as its a point of interest in the commoditisation conversation.
We have to assume that LLMs will eventually start to plateau a bit, in terms of performance, and LLM providers clearly already have an eye on the wider broad feature-sets that might be useful to try to establish or maintain their market dominance.
Perplexity became the big gen-AI search player, and ChatGPT replicated it. Claude added computer-operation API, OpenAI replicated it. For now, the LLMs continue to primarily compete on performance, but this will start to change.
Claude have added a citation functionality for its API, so if you are using it RAG style (providing expert source data along with a question), Claude’s API can now provide citation to your source material in the generated text. Assuming this performs well, this is going to be a massive piece of tech that everyone building RAG/data style platforms can utilise as useful (and often replace tech lots of people have already built to solve this problem).
This kind of feature is also incredibly sticky (helps improve user retention) - if you build a gen AI app that uses Claude’s citations and then want to move to a new model because its way cheaper, for example, you are stuck with the question of whether you keep paying for the citation feature (as it’s the kind of feature you can’t really remove from your app once its out there).